April 10 2024

Gentoo Linux becomes an SPI associated project
![]()
As of this March, Gentoo Linux has become an Associated Project of Software in the Public Interest, see also the formal invitation by the Board of Directors of SPI. Software in the Public Interest (SPI) is a non-profit corporation founded to act as a fiscal sponsor for organizations that develop open source software and hardware. It provides services such as accepting donations, holding funds and assets, … SPI qualifies for 501(c)(3) (U.S. non-profit organization) status. This means that all donations made to SPI and its supported projects are tax deductible for donors in the United States. Read on for more details…
Questions & Answers
Why become an SPI Associated Project?
Gentoo Linux, as a collective of software developers, is pretty good at being a Linux distribution. However, becoming a US federal non-profit organization would increase the non-technical workload.
The current Gentoo Foundation has bylaws restricting its behavior to that of a non-profit, is a recognized non-profit only in New Mexico, but a for-profit entity at the US federal level. A direct conversion to a federally recognized non-profit would be unlikely to succeed without significant effort and cost.
Finding Gentoo Foundation trustees to take care of the non-technical work is an ongoing challenge. Robin Johnson (robbat2), our current Gentoo Foundation treasurer, spent a huge amount of time and effort with getting bookkeeping and taxes in order after the prior treasurers lost interest and retired from Gentoo.
For these reasons, Gentoo is moving the non-technical organization overhead to Software in the Public Interest (SPI). As noted above, SPI is already now recognized at US federal level as a full-fleged non-profit 501(c)(3). It also handles several projects of similar type and size (e.g., Arch and Debian) and as such has exactly the experience and background that Gentoo needs.
What are the advantages of becoming an SPI Associated Project in detail?
Financial benefits to donors:
- tax deductions [1]
Financial benefits to Gentoo:
- matching fund programs [2]
- reduced organizational complexity
- reduced administration costs [3]
- reduced taxes [4]
- reduced fees [5]
- increased access to non-profit-only sponsorship [6]
Non-financial benefits to Gentoo:
- reduced organizational complexity, no “double-headed beast” any more
- less non-technical work required
[1] Presently, almost no donations to the Gentoo Foundation provide a tax benefit for donors anywhere in the world. Becoming a SPI Associated Project enables tax benefits for donors located in the USA. Some other countries do recognize donations made to non-profits in other jurisdictions and provide similar tax credits.
[2] This also depends on jurisdictions and local tax laws of the donor, and is often tied to tax deductions.
[3] The Gentoo Foundation currently pays $1500/year in tax preparation costs.
[4] In recent fiscal years, through careful budgetary planning on the part of the Treasurer and advice of tax professionals, the Gentoo Foundation has used depreciation expenses to offset taxes owing; however, this is not a sustainable strategy.
[5] Non-profits are eligible for reduced fees, e.g., of Paypal (savings of 0.9-1.29% per donation) and other services.
[6] Some sponsorship programs are only available to verified 501(c)(3) organizations
Can I still donate to Gentoo, and how?
Yes, of course, and please do so! For the start, you can go to SPI’s Gentoo page and scroll down to the Paypal and Click&Pledge donation links. More information and more ways will be set up soon. Keep in mind, donations to Gentoo via SPI are tax-deductible in the US!
In time, Gentoo will contact existing recurring donors, to aid transitions to SPI’s donation systems.
What will happen to the Gentoo Foundation?
Our intention is to eventually transfer the existing assets to SPI and dissolve the Gentoo Foundation. The precise steps needed on the way to this objective are still under discussion.
Does this affect in any way the European Gentoo e.V.?
No. Förderverein Gentoo e.V. will continue to exist independently. It is also recognized to serve public-benefit purposes (§ 52 Fiscal Code of Germany), meaning that donations are tax-deductible in the E.U.
April 01 2024

The interpersonal side of the xz-utils compromise


While everyone is busy analyzing the highly complex technical details of the recently discovered xz-utils compromise that is currently rocking the internet, it is worth looking at the underlying non-technical problems that make such a compromise possible. A very good write-up can be found on the blog of Rob Mensching...
March 15 2024

Optimizing parallel extension builds in PEP517 builds

The distutils (and therefore setuptools) build system supports building C extensions in parallel, through the use of -j (--parallel) option, passed either to build_ext or build command. Gentoo distutils-r1.eclass has always passed these options to speed up builds of packages that feature multiple C files.
However, the switch to PEP517 build backend made this problematic. While the backend uses the respective commands internally, it doesn’t provide a way to pass options to them. In this post, I’d like to explore the different ways we attempted to resolve this problem, trying to find an optimal solution that would let us benefit from parallel extension builds while preserving minimal overhead for packages that wouldn’t benefit from it (e.g. pure Python packages). I will also include a fresh benchmark results to compare these methods.
The history
The legacy build mode utilized two ebuild phases: the compile phase during which the build command was invoked, and the install phase during which install command was invoked. An explicit command invocation made it possible to simply pass the -j option.
When we initially implemented the PEP517 mode, we simply continued calling esetup.py build, prior to calling the PEP517 backend. The former call built all the extensions in parallel, and the latter simply reused the existing build directory.
This was a bit ugly, but it worked most of the time. However, it suffered from a significant overhead from calling the build command. This meant significantly slower builds in the vast majority of packages that did not feature multiple C source files that could benefit from parallel builds.
The next optimization was to replace the build command invocation with more specific build_ext. While the former also involved copying all .py files to the build directory, the latter only built C extensions — and therefore could be pretty much a no-op if there were none. As a side effect, we’ve started hitting rare bugs when custom setup.py scripts assumed that build_ext is never called directly. For a relatively recent example, there is my pull request to fix build_ext -j… in pyzmq.
I’ve followed this immediately with another optimization: skipping the call if there were no source files. To be honest, the code started looking messy at this point, but it was an optimization nevertheless. For the no-extension case, the overhead of calling esetup.py build_ext was replaced by the overhead of calling find to scan the source tree. Of course, this still had some risk of false positives and false negatives.
The next optimization was to call build_ext only if there were at least two files to compile. This mostly addressed the added overhead for packages building only one C file — but of course it couldn’t resolve all false positives.
One more optimization was to make the call conditional to DISTUTILS_EXT variable. While the variable was introduced for another reason (to control adding debug flag), it provided a nice solution to avoid both most of the false positives (even if they were extremely rare) and the overhead of calling find.
The last step wasn’t mine. It was Eli Schwartz’s patch to pass build options via DIST_EXTRA_CONFIG. This provided the ultimate optimization — instead of trying to hack a build_ext call around, we were finally able to pass the necessary options to the PEP517 backend. Needless to say, it meant not only no false positives and no false negatives, but it effectively almost eliminated the overhead in all cases (except for the cost of writing the configuration file).
The timings
| Django 5.0.3 | Cython 3.0.9 | ||||
|---|---|---|---|---|---|
| Serial PEP517 build | 5.4 s | 46.7 s | |||
| build | total | 3.1 s | 8.4 s | 20.8 s | 23.5 s |
| PEP517 | 5.3 s | 2.7 s | |||
| build_ext | total | 0.6 s | 6 s | 20.8 s | 23.5 s |
| PEP517 | 5.4 s | 2.7 s | |||
| find + build_ext | total | 0.06 s | 5.5 s | 20.9 s | 23.6 s |
| PEP517 | 5.4 s | 2.7 s | |||
| Parallel PEP517 build | 5.4 s | 22.8 s | |||

For a pure Python package (django here), the table clearly shows how successive iterations have reduced the overhead from parallel build supports, from roughly 3 seconds in the earliest approach, resulting in 8.4 s total build time, to the same 5.4 s as the regular PEP517 build.
For Cython, all but the ultimate solution result in roughly 23.5 s total, half of the time needed for a serial build (46.7 s). The ultimate solution saves another 0.8 s on the double invocation overhead, giving the final result of 22.8 s.
Test data and methodology
The methods were tested against two packages:
- Django 5.0.3, representing a moderate size pure Python package, and
- Cython 3.0.9, representing a package with a moderate number of C extensions.
Python 3.12.2_p1 was used for testing. The timings were done using time command from bash. The results were averaged from 5 warm cache test runs. Testing was done on AMD Ryzen 5 3600, with pstates boost disabled.
The PEP517 builds were performed using the following command:
python3.12 -m build -nwx
The remaining commands and conditions were copied from the eclass. The test scripts, along with the results, spreadsheet and plot source can be found in the distutils-build-bench repository.
March 13 2024
The story of distutils build directory in Gentoo
The Python distutils build system, as well as setuptools (that it was later merged into), used a two-stage build: first, a build command would prepare a built package version (usually just copy the .py files, sometimes compile Python extensions) into a build directory, then an install command would copy them to the live filesystem, or a staging directory. Curious enough, distutils were an early adopter of out-of-source builds — when used right (which often enough wasn’t the case), no writes would occur in the source directory and all modifications would be done directly in the build directory.
Today, in the PEP517 era, two-stage builds aren’t really relevant anymore. Build systems were turned into black boxes that spew wheels. However, setuptools still internally uses the two-stage build and the build directory, and therefore it still remains relevant to Gentoo eclasses. In this post, I’d like to shortly tell how we dealt with it over the years.
Act 1: The first overrides
Normally, distutils would use a build directory of build/lib*, optionally suffixed for platform and Python version. This was reasonably good most of the time, but not good enough for us. On one hand, it didn’t properly distinguish CPython and PyPy (and it wouldn’t for a long time, until Use cache_tag in default build_platlib dir PR). On the other, the directory name would be hard to get, if ebuilds ever needed to do something about it (and we surely did).
Therefore, the eclass would start overriding build directories quite early on. We would start by passing --build-base to the build command, then add --build-lib to make the lib subdirectory path simpler, then replace it with separate --build-platlib and --build-purelib to workaround build systems overriding one of them (wxPython, if I recall correctly).
The eclass would class this mode “out-of-source build” and use a dedicated BUILD_DIR variable to refer to the dedicated build directory. Confusingly, “in-source build” would actually indicate a distutils-style out-of-source build in the default build subdirectory, and the eclass would create a separate copy of the sources for every Python target (effectively permitting in-source modifications).
The last version of code passing --build* options.
Act 2: .pydistutils.cfg
The big problem with the earlier approach is that you’d have to pass the options every time setup.py is invoked. Given the design of option passing in distutils, this effectively meant that you needed to repeatedly invoke the build commands (otherwise you couldn’t pass options to it).
The next step would be to replace this logic by using .pydistutils.cfg configuration file. The file, placed in HOME (also overridden in eclass) would allow us to set option values without actually having to pass specific commands on the command-line. The relevant logic, added in September 2013 (commit: Use pydistutils.cfg to set build-dirs instead of passing commands explicitly…), remains in the eclass even today. However, since the PEP517 build mode stopped using this file, it is used only in legacy mode.
The latest version of the code writing .pydistutils.cfg.
Act 3: Messy PEP517 mode
One of the changes caused by building in PEP517 mode was that .pydistutils.cfg started being ignored. This implied that setuptools were using the default build directory again. It wasn’t such a big deal anymore — since we no longer used proper separation between the two build stages, and we no longer needed to have any awareness of the intermediate build directory, the path didn’t matter per se. However, it meant CPython and PyPy started sharing the same build directory again — and since setuptools install stage picks everything up from that directory, it meant that extensions built for PyPy3.10 would be installed to CPython3.10 directory!
How did we deal with that? Well, at first I’ve tried calling setup.py clean -a. It was kinda ugly, especially that it meant combining setup.py calls with PEP517 invocations — but then, we were already calling setup.py build to take advantage of parallel build jobs when building extensions, and it worked. For a time.
Unfortunately, it turned out that some packages override the clean command and break our code, or even literally block calling it. So the next step was to stop being fancy and literally call rm -rf build. Well, this was ugly, but — again — it worked.
Act 4: Back to the config files
As I’ve mentioned before, we continued to call the build command in PEP517 mode, in order to enable building C extensions in parallel via the -j option. Over time, this code grew in complexity — we’ve replaced the call with more specific build_ext, then started adding heuristics to avoid calling it when unnecessary (a no-op setup.py build_ext call slowed pure Python package builds substantially).
Eventually, Eli Schwartz came up with a great alternative — using DIST_EXTRA_CONFIG to provide a configuration file. This meant that we could replace both setup.py invocations — by using the configuration file both to specify the job count for extension builds, and to use a dedicated build directory.
The change originally was done only for the explicit use of setuptools build backend. As a result, we’ve missed a bunch of “indirect” setuptools uses — other setuptools-backed PEP517 backends (jupyter-builder, pbr), backends using setuptools conditionally (pdm-backend), custom wrappers over setuptools and… dev-python/setuptools package itself (“standalone” backend). We’ve learned about it the hard way when setuptools stopped implicitly ignoring the build directory as a package name — and effectively a subsequent build collected a copy of the previous build as a build package. Yep, we’ve ended up with a monster of /usr/lib/python3.12/site-packages/build/lib/build/lib/setuptools.
So we approach the most recent change: enabling the config for all backends. After all, we’re just setting an environment variable, so others build backends will just ignore it.
And so, we’ve came full circle. We’ve enabled configuration files early on, switched to other hacks when PEP517 builds broke that and eventually returned to unconditionally using configuration files.
February 23 2024

Gentoo RISC-V Image for the Allwinner Nezha D1

Motivation
The Allwinner Nezha D1 SoC was one of the first available RISC-V single-board computers (SBC) crowdfounded and released in 2021. According to the manufacturer, “it is the world’s first mass-produced development board that supports 64bit RISC-V instruction set and Linux system.”.
Installing Gentoo on this system usually involved grabbing one existing image, like the Fedora one, and swapping the userland with a Gentoo stage3.
Bootstrapping via a third-party image is now no longer necessary.
A Gentoo RISC-V Image for the Nezha D1
I have uploaded a, for now, experimental Gentoo RISCV-V Image for the Nezha D1 at
https://dev.gentoo.org/~flow/gymage/
Simply dd(rescue) the image onto a SD-Card and plug that card into your board.
Now, you could either connect to the UART or plug in a Ethernet cable to get to a login prompt.
UART
You typically want to connect a USB-to-UART adapter to the board. Unlike other SBCs, the debug UART on the Nezha D1 is clearly labeled with GND, RX, and TX. Using the standard ThunderFly color scheme, this resolves to black for ground (GND), green for RX, and white for TX.
Then fire up your favorite serial terminal
and power on the board.
Note: Your milleage may vary. For example, you probably want your user to be a member of the ‘dialout’ group to access
the serial port. The device name of your USB-to-UART adapter may not be /dev/ttyUSB0.
SSH
Ethernet port of the board is configured to use DHCP for network configuration. A SSH daemon is listening on port 22.
Login
The image comes with a ‘root’ user whose password is set to ‘root’. Note that you should change this password as soon as possible.
gymage
The image was created using the gymage tool.
I envision the gymage to become an easy-to-use tool that allows users to create up-to-date Gentoo images for single-board computers. The tool is in an early stage with some open questions. However, you are free to try it. The source code of gymage is hosted at https://gitlab.com/flow/gymage, and feedback is, as always, appreciated.
Stay tuned for another blog post about gymage once it matures further.
February 04 2024
Gentoo x86-64-v3 binary packages available


End of December 2023 we already made our official announcement of binary Gentoo package hosting. The initial package set for amd64 was and is base-line x86-64, i.e., it should work on any 64bit Intel or AMD machine. Now, we are happy to announce that there is also a separate package set using the extended x86-64-v3 ISA (i.e., microarchitecture level) available for the same software. If your hardware supports it, use it and enjoy the speed-up! Read on for more details…
Questions & Answers
How can I check if my machine supports x86-64-v3?
The easiest way to do this is to use glibc’s dynamic linker:
larry@noumea ~ $ ld.so --help
Usage: ld.so [OPTION]... EXECUTABLE-FILE [ARGS-FOR-PROGRAM...]
You have invoked 'ld.so', the program interpreter for dynamically-linked
ELF programs. Usually, the program interpreter is invoked automatically
when a dynamically-linked executable is started.
[...]
[...]
Subdirectories of glibc-hwcaps directories, in priority order:
x86-64-v4
x86-64-v3 (supported, searched)
x86-64-v2 (supported, searched)
larry@noumea ~ $
As you can see, this laptop supports x86-64-v2 and x86-64-v3, but not x86-64-v4.
How do I use the new x86-64-v3 packages?
On your amd64 machine, edit the configuration file in /etc/portage/binrepos.conf/
that defines the URI from where the packages are downloaded, and replace x86-64 with
x86-64-v3. E.g., if you have so far
sync-uri = https://distfiles.gentoo.org/releases/amd64/binpackages/17.1/x86-64/
then you change the URI to
sync-uri = https://distfiles.gentoo.org/releases/amd64/binpackages/17.1/x86-64-v3/
That’s all.
Why don’t you have x86-64-v4 packages?
There’s not yet enough hardware and people out there that could use them.
We could start building such packages at any time (our build host is new and shiny), but for now we recommend you build from source and use your own CFLAGS then. After all, if your machine supports x86-64-v4, it’s definitely fast…
Why is there recently so much noise about x86-64-v3 support in Linux distros?
Beats us. The ISA is 9 years old (just the tag x86-64-v3 was slapped onto it recently), so you’d think binaries would have been generated by now. With Gentoo you could’ve done (and probably have done) it all the time.
That said, in some processor lines (i.e. Atom), support for this instruction set was introduced rather late (2021).
January 22 2024
2023 in retrospect & happy new year 2024!
 A Happy New Year 2024 to all of you! We hope you enjoyed the fireworks; we tried to contribute
to these too with the binary package news just before new year! That’s not the only thing in Gentoo that
was new in 2023 though; as in the previous years, let’s look back and give it a review.
A Happy New Year 2024 to all of you! We hope you enjoyed the fireworks; we tried to contribute
to these too with the binary package news just before new year! That’s not the only thing in Gentoo that
was new in 2023 though; as in the previous years, let’s look back and give it a review.
Gentoo in numbers
The number of commits to the main ::gentoo repository has remained at an overall high level in 2023, only slightly lower from 126682 to 121000. The number of commits by external contributors has actually increased from 10492 to 10708, now across 404 unique external authors.
GURU, our user-curated repository with a trusted user model, is still attracting a lot of potential developers. We have had 5045 commits in 2023, a slight decrease from 5751 in 2022. The number of contributors to GURU has increased clearly however, from 134 in 2022 to 158 in 2023. Please join us there and help packaging the latest and greatest software. That’s the ideal preparation for becoming a Gentoo developer!
On the Gentoo bugtracker bugs.gentoo.org, we’ve had 24795 bug reports created in 2023, compared to 26362 in 2022. The number of resolved bugs shows a similar trend, with 22779 in 2023 compared to 24681 in 2022. Many of these bugs are stabilization requests; a possible interpretation is that stable Gentoo is becoming more and more current, catching up with new software releases.
New developers
In 2023 we have gained 3 new Gentoo developers. They are in chronological order:
-
Arsen Arsenović (arsen):
Arsen joined up as a developer right at the start of the year in January from Belgrade, Serbia. He’s a computer science student interested in both maths and music, active in many different free software projects, and has already made his impression, e.g., in our emacs and toolchain projects.
-
Paul Fox (ris): After already being very active in our Wiki for some time, Paul joined in March as developer from France. Activity on our wiki and documentation quality will certainly grow much further with his help.
-
Petr Vaněk (arkamar):
Petr Vaněk, from Prague, Czech Republic, joined the ranks of our developers in November. Gentoo user since 2009, craft beer enthusiast, and Linux kernel contributor, he has already been active in very diverse corners of Gentoo.
Featured changes and news
Let’s now look at the major improvements and news of 2023 in Gentoo.
Distribution-wide Initiatives
-
 Binary package hosting: Gentoo shockingly now also provides
binary packages, for easier and faster installation! For amd64 and arm64, we’ve got
a stunning >20 GByte of packages on our mirrors, from LibreOffice
to KDE Plasma and from Gnome to Docker.
Also, would you think 9-year old x86-64-v3 is still experimental?
We have it already
on our mirrors! For all other architectures and ABIs, the binary package files used for building the
installation stages (including the build tool chain) are available for download.
Binary package hosting: Gentoo shockingly now also provides
binary packages, for easier and faster installation! For amd64 and arm64, we’ve got
a stunning >20 GByte of packages on our mirrors, from LibreOffice
to KDE Plasma and from Gnome to Docker.
Also, would you think 9-year old x86-64-v3 is still experimental?
We have it already
on our mirrors! For all other architectures and ABIs, the binary package files used for building the
installation stages (including the build tool chain) are available for download. -
New 23.0 profiles in preparation: A new profile version, i.e. a collection of presets and configurations, is at the moment undergoing internal preparation and testing for all architectures. It’s not ready yet, but will integrate more toolchain hardening by default, as well as fix a lot of internal inconsistencies. Stay tuned for an announcement with more details in the near future.
-
Modern C: Work continues on porting Gentoo, and the Linux userland at large, to Modern C. This is a real marathon effort rather than a sprint (just see our tracker bug for it). Our efforts together with the same project ongoing in Fedora have already helped many upstreams, which have accepted patches in preparation for GCC 14 (that starts to enforce the modern language usage).
-
 Event presence: At the Free and Open Source
Developers European Meeting (FOSDEM) 2023, the Free and Open Source Software
Conference (FrOSCon) 2023, and the Chemnitzer
Linux-Tage (CLT) 2023, Gentoo had a booth with mugs, stickers, t-shirts, and of course the famous
self-compiled buttons.
Event presence: At the Free and Open Source
Developers European Meeting (FOSDEM) 2023, the Free and Open Source Software
Conference (FrOSCon) 2023, and the Chemnitzer
Linux-Tage (CLT) 2023, Gentoo had a booth with mugs, stickers, t-shirts, and of course the famous
self-compiled buttons. -
 Google Summer of Code: In 2023 Gentoo had another successful year participating in the
Google Summer of Code. We had three contributors
completing their projects; you can find out more about them by visiting the
Gentoo GSoC blog. We thank our contributors Catcream, LabBrat, and
Listout, and also all the developers who took the time to mentor them.
Google Summer of Code: In 2023 Gentoo had another successful year participating in the
Google Summer of Code. We had three contributors
completing their projects; you can find out more about them by visiting the
Gentoo GSoC blog. We thank our contributors Catcream, LabBrat, and
Listout, and also all the developers who took the time to mentor them. -
Online workshops: Our German support, Gentoo e.V., organized this year 6 online workshops on building and improving ebuilds. This will be continued every two months in the upcoming year.
-
 Documentation on wiki.gentoo.org has been making great progress as
always. This past year the contributor’s
guide, article writing guidelines, and
help pages were updated to
give the best possible start to anyone ready to lend a hand. The Gentoo Handbook got updates,
and a new changelog. Of course much documentation was fixed, extended, or updated, and quite
a few new pages were created. We hope to see even more activity in the new year, and hopefully
some new contributors - editing documentation is a particularly easy area to
start contributing to Gentoo in, please
give it a try!
Documentation on wiki.gentoo.org has been making great progress as
always. This past year the contributor’s
guide, article writing guidelines, and
help pages were updated to
give the best possible start to anyone ready to lend a hand. The Gentoo Handbook got updates,
and a new changelog. Of course much documentation was fixed, extended, or updated, and quite
a few new pages were created. We hope to see even more activity in the new year, and hopefully
some new contributors - editing documentation is a particularly easy area to
start contributing to Gentoo in, please
give it a try!
Architectures
-
 Alpha: Support for the DEC Alpha
architecture was revived, with a massive keywording effort going on. While not perfectly
complete yet, we are very close to a fully consistent dependency tree and package set for alpha again.
Alpha: Support for the DEC Alpha
architecture was revived, with a massive keywording effort going on. While not perfectly
complete yet, we are very close to a fully consistent dependency tree and package set for alpha again. -
 musl: Support for the lightweight musl libc has
been added to the architectures MIPS (o32) and m68k, with corresponding profiles in the Gentoo
repository and corresponding installation stages and binary packages available for download. Enjoy!
musl: Support for the lightweight musl libc has
been added to the architectures MIPS (o32) and m68k, with corresponding profiles in the Gentoo
repository and corresponding installation stages and binary packages available for download. Enjoy!
Packages
-
 .NET: The Gentoo Dotnet project
has significantly
improved support for building
.NET-based software, using the nuget, dotnet-pkg-base, and dotnet-pkg eclasses.
Now we’re ready for packages depending on the .NET ecosystem and for
developers using dotnet-sdk on Gentoo. New software requiring .NET is constantly
being added to the main Gentoo tree. Recent additions include PowerShell for Linux,
Denaro (a finance application), Pinta (a graphics program), Ryujinx (a NS emulator)
and many other aimed straight at developing .NET projects.
.NET: The Gentoo Dotnet project
has significantly
improved support for building
.NET-based software, using the nuget, dotnet-pkg-base, and dotnet-pkg eclasses.
Now we’re ready for packages depending on the .NET ecosystem and for
developers using dotnet-sdk on Gentoo. New software requiring .NET is constantly
being added to the main Gentoo tree. Recent additions include PowerShell for Linux,
Denaro (a finance application), Pinta (a graphics program), Ryujinx (a NS emulator)
and many other aimed straight at developing .NET projects. -
 Java: OpenJDK 21 has been introduced for amd64, arm64, ppc64, and x86!
Java: OpenJDK 21 has been introduced for amd64, arm64, ppc64, and x86! -
Python: In the meantime the default Python version in Gentoo has reached Python 3.11. Additionally we have also Python 3.12 available stable - again we’re fully up to date with upstream.
-
 PyPy3 compatibility for scientific Python:
While some packages (numexpr, pandas, xarray) are at the moment still undergoing upstream bug fixing,
more and more scientific Python packages have been adapted in Gentoo and upstream for
the speed-optimized Python variant PyPy. This can provide a nice performance boost for
numerical data analysis…
PyPy3 compatibility for scientific Python:
While some packages (numexpr, pandas, xarray) are at the moment still undergoing upstream bug fixing,
more and more scientific Python packages have been adapted in Gentoo and upstream for
the speed-optimized Python variant PyPy. This can provide a nice performance boost for
numerical data analysis… -
Signed kernel modules and (unified) kernel images: We now support signing of both in-tree and out-of-tree kernel modules and kernel images. This is useful for those who would like the extra bit of verification offered by Secure Boot, which is now easier than ever to set up on Gentoo systems! Additionally, our kernel install scripts and eclasses are now fully compatible with Unified Kernel Images and our prebuilt gentoo-kernel-bin can now optionally install an experimental pregenerated generic Unified Kernel Image.
-
 The GAP System:
A new dev-gap package category has arrived with about sixty packages.
GAP is a popular system for computational
discrete algebra, with particular emphasis on Computational Group
Theory. GAP consists of a programming language, a library of thousands
of functions implementing algebraic algorithms written in the GAP
language, and large data libraries of algebraic objects. It has
its own
package ecosystem, mostly written in the GAP language with a few C components.
The GAP System:
A new dev-gap package category has arrived with about sixty packages.
GAP is a popular system for computational
discrete algebra, with particular emphasis on Computational Group
Theory. GAP consists of a programming language, a library of thousands
of functions implementing algebraic algorithms written in the GAP
language, and large data libraries of algebraic objects. It has
its own
package ecosystem, mostly written in the GAP language with a few C components.
Physical and Software Infrastructure
-
 Portage improvements: A significant amount of work went into enhancing our
package manager, Portage, to better support binary package deployment. Users building
their own binary packages and setting up their own infrastructure will certainly benefit
from it too.
Portage improvements: A significant amount of work went into enhancing our
package manager, Portage, to better support binary package deployment. Users building
their own binary packages and setting up their own infrastructure will certainly benefit
from it too. -
packages.gentoo.org: The development of Gentoo’s package database website, packages.gentoo.org, has picked up speed, with new features for maintainer, category, and arch pages, and Repology integration. Many optimization were done for the backend database queries and the website should now feel faster to use.
-
 pkgdev bugs: A new developer tool called pkgdev bugs enables us now to
simplify the procedure for filing new stable requests bugs a lot. By just giving it
version lists (which can be generated by other tools),
pkgdev bugs can be used to compute dependencies, cycles, merges, and will file
the bugs for the architecture teams / testers. This allows us to step ahead much faster
with package stabilizations.
pkgdev bugs: A new developer tool called pkgdev bugs enables us now to
simplify the procedure for filing new stable requests bugs a lot. By just giving it
version lists (which can be generated by other tools),
pkgdev bugs can be used to compute dependencies, cycles, merges, and will file
the bugs for the architecture teams / testers. This allows us to step ahead much faster
with package stabilizations.
Finances of the Gentoo Foundation
-
 Income: The Gentoo Foundation took in approximately $18,500 in fiscal year 2023;
the majority (over 80%) were individual cash donations from the community.
Income: The Gentoo Foundation took in approximately $18,500 in fiscal year 2023;
the majority (over 80%) were individual cash donations from the community. -
Expenses: Our expenses in 2023 were, as split into the usual three categories, operating expenses (for services, fees, …) $6,000, only minor capital expenses (for bought assets), and depreciation expenses (value loss of existing assets) $20,000.
-
Balance: We have about $101,000 in the bank as of July 1, 2023 (which is when our fiscal year 2023 ends for accounting purposes). The draft finanical report for 2023 is available on the Gentoo Wiki.
Thank you!
Obviously this is not all Gentoo development that happened in 2023. From KDE to GNOME, from kernels to scientific software, you can find much more if you look at the details. As every year, we would like to thank all Gentoo developers and all who have submitted contributions for their relentless everyday Gentoo work. As a volunteer project, Gentoo could not exist without them. And if you are interested and would like to contribute, please join us and help us make Gentoo even better!
September 21 2021
Experimental binary Gentoo package hosting (amd64)

So what do we have, and how can you use it?
- The server builds an assortment of stable amd64 packages, with the use-flags as present in an unmodified 17.1/desktop/plasma/systemd profile (the only necessary change is USE=bindist).
- The packages can be used on all amd64 profiles that differ from desktop/plasma/systemd only by use-flag settings. This includes 17.1, 17.1/desktop/*, 17.1/no-multilib, 17.1/systemd, but not anything containing selinx, hardened, developer, musl, or a different profile version such as 17.0.
- Right now, the package set includes kde-plasma/plasma-meta, kde-apps/kde-apps-meta, app-office/libreoffice, media-gfx/gimp, media-gfx/inkscape, and of course all their dependencies. More will possibly be added.
- CFLAGS are chosen such that the packages will be usable on all amd64 (i.e., x86-64) machines.
To use the packages, I recommend the following steps: First, create a file /etc/portage/binrepos.conf with the following content:
[binhost]
priority = 9999
sync-uri = https://gentoo.osuosl.org/experimental/amd64/binpkg/default/linux/17.1/x86-64/
You can pick a different mirror according to your preferences (but also see the remarks below). Then, edit /etc/portage/make.conf, and add the following EMERGE_DEFAULT_OPTS (in addition to flags that you might already have there):
EMERGE_DEFAULT_OPTS="--binpkg-respect-use=y --getbinpkg=y"
And that's it. Your next update should download the package index and use binary packages whenever the versions and use-flag settings match. Everything else is compiled as usual.
What is still missing, and what are the limitations and caveats?
- Obviously, the packages are not optimized for your processor.
- Right now, the server only carries packages for the use-flag settings in an unmodified 17.1/desktop/plasma/systemd profile. If you use other settings, you will end up compiling part of your packages (which is not really a probem, you just lose the benefit of the binary download). It is technically possible to provide binary packages for different use-flag settings at the same URL, and eventually it will be implemented if this experiment succeeds.
- At the moment, no cryptographic signing of the binary packages is in place yet. This is the main reason why I'm talking about an experiment. Effectively you trust our mirror admins and the https protocol. Package signing and verification is in preparation, and before the binary package hosting "moves into production", it will be enforced.
December 29 2023
Gentoo goes Binary!
You probably all know Gentoo Linux as your favourite source-based distribution. Did you know that our package manager, Portage, already for years also has support for binary packages, and that source- and binary-based package installations can be freely mixed?
To speed up working with slow hardware and for overall convenience, we’re now also offering binary packages for download and direct installation! For most architectures, this is limited to the core system and weekly updates - not so for amd64 and arm64 however. There we’ve got a stunning >20 GByte of packages on our mirrors, from LibreOffice to KDE Plasma and from Gnome to Docker. Gentoo stable, updated daily. Enjoy! And read on for more details!
Questions & Answers
How can I set up my existing Gentoo installation to use these packages?
Quick setup instructions for
the most common cases can be found in our wiki. In short, you need to create a configuration
file in /etc/portage/binrepos.conf/.
In addition, we have a rather neat binary package guide on our Wiki that goes into much more detail.
What do I have to do with a new stage / new installation?
New stages already contain the suitable /etc/portage/binrepos.conf/gentoobinhost.conf. You are
good to go from the start, although you may want to replace the src-uri
setting in there with an URI pointing to the corresponding directory on a
local mirror.
$ emerge -uDNavg @world
What compile settings, use flags, … do the ‘‘normal’’ amd64 packages use?
The binary packages under amd64/binpackages/17.1/x86-64 are compiled using
CFLAGS="-march=x86-64 -mtune=generic -O2 -pipe" and will work with any amd64 / x86-64 machine.
The available useflag settings and versions correspond to the stable packages
of the amd64/17.1/nomultilib (i.e., openrc), amd64/17.1/desktop/plasma/systemd,
and amd64/17.1/desktop/gnome/systemd profiles. This should provide fairly large
coverage.
What compile settings, use flags, … do the ‘‘normal’’ arm64 packages use?
The binary packages under arm64/binpackages/17.0/arm64 are compiled using
CFLAGS="-O2 -pipe" and will work with any arm64 / AArch64 machine.
The available useflag settings and versions correspond to the stable packages
of the arm64/17.0 (i.e., openrc), arm64/17.0/desktop/plasma/systemd,
and arm64/17.0/desktop/gnome/systemd profiles.
But hey, that’s not optimized for my CPU!
Tough luck. You can still compile packages yourself just as before!
What settings do the packages for other architectures and ABIs use?
The binary package hosting is wired up with the stage builds. Which means, for about every stage there is a binary package hosting which covers (only) the stage contents and settings. There are no further plans to expand coverage for now. But hey, this includes the compiler (gcc or clang) and the whole build toolchain!
Are the packages cryptographically signed?
Yes, with the same key as the stages.
Are the cryptographic signatures verified before installation?
Yes, with one limitation (in the default setting).
Portage knows two binary package formats, XPAK (old) and GPKG (new). Only GPKG supports cryptographic signing. Until recently, XPAK was the default setting (and it may still be the default on your installation since this is not changed during upgrade, but only at new installation).
The new, official Gentoo binary packages are all in GPKG format. GPKG packages have their signature verified, and if this fails, installation is refused. To avoid breaking compatibility with old binary packages, by default XPAK packages (which do not have signatures) can still be installed however.
If you want to require verified signatures (which is something we strongly recommend),
set FEATURES="binpkg-request-signature" in make.conf. Then, obviously, you can also
only use GPKG packages.
I get an error that signatures cannot be verified.
Try running the Gentoo Trust Tool getuto as root.
$ getuto
This should set up the required key ring with the Gentoo Release Engineering keys for Portage.
If you have FEATURES="binpkg-request-signature" enabled in make.conf, then getuto
is called automatically before every binary package download operation, to make sure
that key updates and revocations are imported.
I’ve made binary packages myself and portage refuses to use them now!
Well, you found the side effect of FEATURES="binpkg-request-signature".
For your self-made packages you will need to set up a signing key and have that key
trusted by the anchor in /etc/portage/gnupg.
The binary package guide on our Wiki will be helpful here.
My download is slow.
Then pretty please use a local mirror
instead of downloading from University of Oregon. You can just edit the URI
in your /etc/portage/binrepos.conf. And yes, that’s safe, because of the
cryptographic signature.
My Portage still wants to compile from source.
If you use useflag combinations deviating from the profile default, then you can’t and won’t use the packages. Portage will happily mix and match though and combine binary packages with locally compiled ones. Gentoo still remains a source-based distribution, and we are not aiming for a full binary-only installation without any compilation at all.
Can I use the packages on a merged-usr system?
Yes. (If anything breaks, then this is a bug and should be reported.)
Can I use the packages with other (older or newer) profile versions?
No. That’s why the src-uri path contains, e.g., “17.1”.
When there’s a new profile version, we’ll also provide new, separate package directories.
Any plans to offer binary packages of ~amd64 ?
Not yet. This would mean a ton of rebuilds… If we offer it one day, it’ll be at a separate URI for technical reasons.
The advice for now is to stick to stable as much as possible, and locally
add in package.accept_keywords whatever packages from testing you want to use.
This means you can still use a large amount of binary packages, and just
compile the rest yourself.
I have found a problem, with portage or a specific package!
Then please ask for advice (on IRC, the forums, or a mailing list) and/or file a bug!
Binary package support has been tested for some time, but with many more people using it edge cases will certainly occur, and quality bug reports are always appreciated!
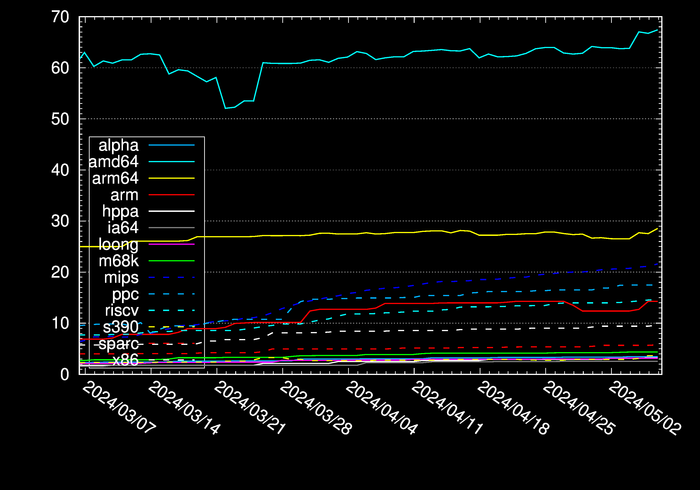
Any pretty pictures?
Of course! Here’s the amount of binary package data in GByte for each architecture…
December 17 2023

.NET in Gentoo in 2023

.NET ecosystem in Gentoo in year 2023
The Gentoo Dotnet project introduced better support for building .NET-based software using the nuget, dotnet-pkg-base and dotnet-pkg eclasses. This opened new opportunities of bringing new packages depending on .NET ecosystem to the official Gentoo ebuild repository and helping developers that use dotnet-sdk on Gentoo.
New software requiring .NET is constantly being added to the main Gentoo tree, among others that is:
- PowerShell for Linux,
- Denaro — finance application,
- Ryujinx — NS emulator,
- OpenRA — RTS engine for Command & Conquer, Red Alert and Dune2k,
- Pinta — graphics program,
- Pablodraw — Ansi, Ascii and RIPscrip art editor,
- Dafny — verification-aware programming language
- many packages aimed straight at developing .NET projects.
Dotnet project is also looking for new maintainers and users who are willing to help out here and there. Current state of .NET in Gentoo is very good but we can still do a lot better.
Special thanks to people who helped out
Links to bugs and announcements
- Bugs
- Github PRs
- Active Gentoo .NET projects
Portage Continuous Delivery
Portage as a CD system
This is a very simple way to use any system with Portage installed as a Continuous Delivery server.
I think for a testing environment this is a valid solution to consider.
Create a repository of software used in your organization
Those articles from the Gentoo Wiki describe how to create a custom ebuild repository (overlay) pretty well:
Set up your repo with eselect-repository
Install the my-org repository:
1
|
eselect repository add my-org git https://git.my-org.local/portage/my-org.git |
Sync my-org:
1
|
emerge --sync my-org |
Install live packages of a your software
First, enable live packages (keywordless) for your my-org repo:
1
|
echo '*/*::my-org' >> /etc/portage/package.accept_keywords/0000_repo_my-org.conf |
Install some packages from my-org:
1
|
emerge -av "=mycategory/mysoftware-9999" |
Install smart-live-rebuild
smart-live-rebuild can automatically update live software packages that use git as their source URL.
Set up cron to run smart-live-rebuild
Refresh your my-org repository every hour:
1
|
0 */1 * * * emerge --sync my-org |
Refresh the main Gentoo tree every other 6th hour:
1
|
0 */6 * * * emerge --sync gentoo |
Run smart-live-rebuild every other 3rd hour:
1
|
0 */3 * * * smart-live-rebuild |
Restarting services after update
All-in-one script
You can either restart all services after successful update:
File: /opt/update.sh
1 2 3 4 5 6 7 8 |
#!/bin/sh set -e smart-live-rebuild systemctl restart my-service-1.service systemctl restart my-service-2.service |
Crontab:
1
|
0 */3 * * * /opt/update.sh |
Via ebuilds pkg_ functions
File: my-service-1.ebuild
1 2 3 |
pkg_postinst() { systemctl restart my-service-1.service } |
More about pkg_postinst:
Example Gentoo overlays
December 07 2023
A format that does one thing well or one-size-fits-all?
The Unix philosophy states that we ought to design programs that “do one thing well”. Nevertheless, the current trend is to design huge monoliths with multiple unrelated functions, with web browsers at the peak of that horrifying journey. However, let’s consider something else.
Does the same philosophy hold for algorithms and file formats? Is it better to design formats that suit a single use case well, and swap between different formats as need arises? Or perhaps it is a better solution to actually design them so they could fit different needs?
Let’s consider this by exploring three areas: hash algorithms, compressed file formats and image formats.
Hash algorithms
Hash, digest, checksum — they have many names, and many uses. To list a few uses of hash functions and their derivatives:
- verifying file integrity
- verifying file authenticity
- generating derived keys
- generating unique keys for fast data access and comparison
Different use cases imply different requirements. The simple CRC algorithms were good enough to check files for random damage but they aren’t suitable for cryptographic purposes. The SHA hashes provide good resistance to attacks but they are too slow to speed up data lookups. That role is much better served by dedicated fast hashes such as xxHash. In my opinion, these are all examples of “do one thing well”.
On the other hand, there is some overlap. More often than not, cryptographic hash functions are used to verify integrity. Then we have modern hashes like BLAKE2 that are both fast and secure (though not as fast as dedicated fast hashes). Argon2 key derivation function builds upon BLAKE2 to improve its security even further, rather than inventing a new hash. These are the examples how a single tool is used to serve different purposes.
Compressed file formats
The purpose of compression, of course, is to reduce file size. However, individual algorithms may be optimized for different kinds of data and different goals.
Probably the oldest category are “archiving” algorithms that focus on providing strong compression and reasonably fast decompression. Back in the day, there were used to compress files in “cold storage” and for transfer; nowadays, they can be used basically for anything that you don’t modify very frequently. The common algorithms from this category include deflate (used by gzip, zip) and LZMA (used by 7z, lzip, xz).
Then, we have very strong algorithms that achieve remarkable compression at the cost of very slow compression and decompression. These are sometimes (but rarely) used for data distribution. An example of such algorithms are the PAQ family.
Then, we have very fast algorithms such as LZ4. They provide worse compression ratios than other algorithms, but they are so fast that they can be used to compress data on the fly. They can be used to speed up data access and transmission by reducing its size with no noticeable overhead.
Of course, many algorithms have different presets. You can run lz4 -9 to get stronger compression with LZ4, or xz -1 to get faster compression with XZ. However, neither the former will excel at compression ratio, nor the latter at speed.
Again, we are seeing different algorithms that “do one thing well”. However, nowadays ZSTD is gaining popularity and it spans a wider spectrum, being capable of both providing very fast compression (but not as fast as LZ4) and quite strong compression. What’s really important is that it’s capable of providing adaptive compression — that is, dynamically adjusting the compression level to provide the best throughput. It switches to a faster preset if the current one is slowing the transmission down, and to a stronger one if there is a potential speedup in that.
Image formats
Let’s discuss image formats now. If we look back far enough, we’d arrive at a time when two image formats were dominating the web. On one hand, we had GIF — with lossless compression, limited color palette, transparency and animations, that made it a good choice for computer-generated images. On the other, we had JPEG — with efficient lossy compression and high color depth suitable for photography. We could see these two as “doing one thing well”.
Then came PNG. PNG is also lossless but provides much higher color depth and improved support for transparency via an alpha channel. While it’s still the format of choice for computer-generated images, it’s also somewhat suitable for photography (but with less efficient compression). With APNG around, it effectively replaces GIF but it also partially overlaps with the use cases for JPEG.
Modern image formats go even further. WebP, AVIF and JPEG XL all support both lossless and lossy compession, high color depths, alpha channel, animation. Therefore, they are suitable both for computer-generated images and for photography. Effectively, they can replace all their predecessors with a “one size fits all” format.
Conclusion
I’ve asked whether it is better to design formats that focus on one specific use case, or whether formats that try to cover a whole spectrum of use cases are better. I’m afraid there’s no easy answer to this question.
We can clearly see that “one-size-fits-all” solutions are gaining popularity — BLAKE2 among hashes, ZSTD in compressed file formats, WebP, AVIF and JPEG XL among image formats. They have a single clear advantage — you need just one tool, one implementation.
Your web browser needs to support only one format that covers both computer-generated graphics using lossless compression and photographs using lossy compression. Different tools can reuse the same BLAKE2 implementation that’s well tested and audited. A single ZSTD library can serve different applications in their distinct use cases.
However, there is still a clear edge to algorithms that are focused on a single use case. xxHash is still faster than any hashes that could be remotely suitable for cryptographic purposes. LZ4 is still faster than ZSTD can be in its lowest compression mode.
The only reasonable conclusion seems to be: there are use cases for both. There are use cases that are best satisfied by a dedicated algorithm, and there are use cases when a more generic solution is better. There are use cases when integrating two different hash algorithms, two different compression libraries into your program, with the overhead involved, is a better choice, than using just one algorithm that fits neither of your two distinct use cases well.
Once again, it feels that a reference to XKCD#927 is appropriate. However, in this particular instance this isn’t a bad thing.
September 05 2023
My thin wrapper for emerge(1)
I’ve recently written a thin wrapper over emerge that I use in my development environment. It does the following:
- set tmux pane title to the first package argument (so you can roughly see what’s emerging on every pane)
- beep meaningfully when emerge finishes (two beeps for success, three for failure),
- run pip check after successful run to check for mismatched Python dependencies.
Here’s the code:
#!/bin/sh
for arg; do
case ${arg} in
-*)
;;
*)
tmux rename-window "${arg}"
break
;;
esac
done
/usr/bin/emerge "${@}"
ret=${?}
if [ "${ret}" -eq 0 ]; then
python3.11 -m pip check | grep -v certifi
else
tput bel
sleep 0.1
fi
tput bel
sleep 0.1
tput bel
exit "${ret}"
August 31 2023

Genpatches Supported Kernel Versions

As part of a an effort to streamline developer capacity, the maintainers of gentoo-sources and genpatches have decided to limit past kernel versions to a maximum of 3 years post initial release.
Notes:
- This impacts all kernels that utlize the official genpatches releases as part of their kernel packages including but not limited to the list here [1]
- sys-kernel/vanilla-sources will continue to follow the upstream release and deprecation schedule. Note that the upstream release schedule is showing their LTS kernel support time frames going from six years to four [2]
- gentoo-kernel will also be following this 3 year kernel support and release policy
- In the past, we only supported two versions. With this change, gentoo-sources will still, if enacted today, support 6 versions.
Why should I not run older kernel versions?
- Upstream maintainer Greg Kroah-Hartman specifically recommends the following list of preferred kernel versions to choose from in order: [3]
- Supported kernel from your favorite Linux distribution
- Latest stable release
- Latest LTS release
- Older LTS release that is still being maintained
Greg specifically called out Gentoo’s method of consistently rolling out kernels with both security/bug fixes early and keeping up with upstream’s releases.
Gentoo still does and will continue to offer a variety of kernels to choose from with this change.
[1] https://dev.gentoo.org/~mpagano/genpatches/kernels.html
[2] https://kernel.org/category/releases.html
[3] http://www.kroah.com/log/blog/2018/08/24/what-stable-kernel-should-i-use/
August 27 2023
Final Report, Automated Gentoo System Updater
Project Goals
Main goal of the project was to write an app that will automatically handle updates on Gentoo Linux systems and send notifications with update summaries. More specifically, I wanted to:
- Simplify the update process for beginners, offering a simpler one-click method.
- Minimize time experienced users spend on routine update tasks, decreasing their workload.
- Ensure systems remain secure and regularly updated with minimal manual intervention.
- Keep users informed of the updates and changes.
- Improve the overall Gentoo Linux user experience.
Progress
Here is a summary of what was done every week with links to my blog posts.
Week 1
Basic system updater is ready. Also prepared a Docker Compose file to run tests in containers. Available functionality:
- update security patches
- update @world
- merge changed configuration files
- restart updated services
- do a post-update clean up
- read elogs
- read news
Links:
Week 2
Packaged Python code, created an ebuild and a GitHub Actions workflow that publishes package to PyPI when commit is tagged.
Links:
Week 3
Fixed issue #7 and answered to issue #8 and fixed bug 908308. Added USE flags to manage dependencies. Improve Bash code stability.
Links:
Week 4
Fixed errors in ebuild, replaced USE flags with optfeature for dependency management. Wrote a blog post to introduce my app and posted it on forums. Fixed a bug in --args flag.
Links:
Week 5
Received some feedback from forums. Coded much of the parser (--report). Improved container testing environment.
Links:
- Improved dockerfiles
Weeks 6 and 7
Completed parser (--report). Also added disk usage calculation before and after the update. Available functionality:
- If the update was successful, report will show:
- updated package names
- package versions in the format “old -> new”
- USE flags of those packages
- disk usage before and after the update
- If the emerge pretend has failed, report will show:
- error type (for now only supports ‘blocked packages’ error)
- error details (for blocked package it will show problematic packages)
Links:
Week 8
Add 2 notification methods (--send-reports) – IRC bot and emails via sendgrid.
Links:
Week 9-10
Improved CLI argument handling. Experimented with different mobile app UI layouts and backend options. Fixed issue #17. Started working on mobile app UI, decided to use Firebase for backend.
Links:
Week 11-12
Completed mobile app (UI + backend). Created a plan to migrate to a custom self-hosted backend based on Django+MongoDB+Nginx in the future. Added --send-reports mobile option to CLI. Available functionality:
- UI
- Login screen: Anonymous login
- Reports screen: Receive and view reports send from CLI app.
- Profile screen: View token, user ID and Sign Out button.
- Backend
- Create anonymous users (Cloud Functions)
- Create user tokens (Cloud Functions)
- Receive tokens in https requests, verify them, and route to users (Cloud Functions)
- Send push notifications (FCM)
- Secure database access with Firestore security rules
Link:
- Pull requests: #18
- Mobile app repository
Final week
Added token encryption with Cloud Functions. Packaged mobile app with Github Actions and published to Google Play Store. Recorded a demo video and wrote gentoo_update User Guide that covers both CLI and mobile app.
Links:
- Demo video
- gentoo_update User Guide
- Packaging Github Actions workflow
- Google Play link
- Release page
Project Status
I would say I’m very satisfied with the current state of the project. Almost all tasks were completed from the proposal, and there is a product that can already be used. To summarize, here is a list of deliverables:
- Source code for gentoo_update CLI app
- gentoo_update CLI app ebuild in GURU repository
- gentoo_update CLI app package in PyPi
- Source code for mobile app
- Mobile app for Andoid in APK
- Mobile app for Android in Google Play
Future Improvements
I plan to add a lot more features to both CLI and mobile apps. Full feature lists can be found in readme’s of both repositories:
Final Thoughts
These 12 weeks felt like a hackathon, where I had to learn new technologies very quickly and create something that works very fast. I faced many challenges and acquired a range of new skills.
Over the course of this project, I coded both Linux CLI applications using Python and Bash, and mobile apps with Flutter and Firebase. To maintain the quality of my work, I tested the code in Docker containers, virtual machines and physical hardware. Additionally, I built and deployed CI/CD pipelines with GitHub Actions to automate packaging. Beyond the technical side, I engaged actively with Gentoo community, utilizing IRC chats and forums. Through these platforms, I addressed and resolved issues on both GitHub and Gentoo Bugs, enriching my understanding and refining my skills.
I also would like to thank my mentor, Andrey Falko, for all his help and support. I wouldn’t have been able to finish this project without his guidance.
In addition, I want to thank Google for providing such a generous opportunity for open source developers to work on bringing forth innovation.
Lastly, I am grateful to Gentoo community for the feedback that’s helped me to improve the project immensely.
gentoo_update User Guide
Introduction
This article will go through the basic usage of gentoo_update CLI tool and the mobile app.
But before that, here is a demo of this project:
gentoo_update CLI App
Installation
gentoo_update is available in GURU overlay and in PyPI. Generally, installing the program from GURU overlay is the preferred method, but PyPI will always have the most recent version.
Enable GURU and install with emerge:
eselect repository enable guru
emerge --ask app-admin/gentoo_update
Alternatively, install from PyPI with pip:
python -m venv .venv_gentoo_update
source .venv_gentoo_update/bin/activate
python -m pip install gentoo_updateUpdate
gentoo_update provides 2 update modes – full and security. Full mode updates @world, and security mode uses glsa-check to find security patches, and installs them if something is found.
By default, when run without flags security mode is selected:
gentoo-update
To update @world, run:
gentoo-update --update-mode full
Full list of available parameters and flags can be accessed with the --help flag. Further examples are detailed in the repository’s readme file.
Once the update concludes, a log file gets generated at /var/log/portage/gentoo_update/log_<date> (or whatever $PORTAGE_LOGDIR is set to). This log becomes the basis for the update report when the --report flag is used, transforming the log details into a structured update report.
Send Report
The update report can be sent through three distinct methods: IRC bot, email, or mobile app.
IRC Bot Method
Begin by registering a user on an IRC server and setting a nickname as outlined in the documentation. After establishing a chat channel for notifications, define the necessary environmental variables and execute the following commands:
export IRC_CHANNEL="#<irc_channel_name>"
export IRC_BOT_NICKNAME="<bot_name>"
export IRC_BOT_PASSWORD="<bot_password>"
gentoo-update --send-report irc
Email via Sendgrid
To utilize Sendgrid, register for an account and generate an API key). After installing the Sendgrid Python library from GURU, save the API key in the environmental variables and use the commands below:
emerge --ask dev-python/sendgrid
export SENDGRID_TO='recipient@email.com'
export SENDGRID_FROM='sender@email.com'
export SENDGRID_API_KEY='SG.****************'
gentoo-update --send-report email
Notifications can also be sent via the mobile app. Details on this method will be elaborated in the following section.
gentoo_update Mobile App
Installation
Mobile app can either be installed from Github or Google Play Store.
Play Store
App can be found by searching ‘gentoo_update’ in the Play Store, or by using this link.
Manual Installation
For manual installation on an Android device, download the APK file from
Releases tab on Github. Ensure you’ve enabled installation from Unknown Sources before proceeding.
Usage
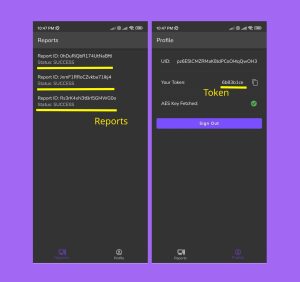
The mobile app consists of three screens: Login, Reports, and Profile.
Upon first use, users will see the Login screen. To proceed, select the Anonymous Login button. This action generates an account with a unique user ID and token, essential for the CLI to send reports.
The Reports screen displays all reports sent using a specific token. Each entry shows the update status and report ID. For an in-depth view of any report, simply tap on it.
On the Profile screen, users can find their 8-character token, which needs to be saved as the GU_TOKEN variable on the Gentoo instance. This screen also shows the AES key status, crucial for decrypting the client-side token as it’s encrypted in the database. To log out, tap the Sign Out button.
Note: Since only Anonymous Login is available, once logged out, returning to the same account isn’t possible.
Contacts
Preferred method for getting help or requesting a new feature for both CLI and mobile apps is by creating an issue in Github:
- gentoo_update CLI issues page
- Mobile app issues page
Or just contact me directly via labbrat_social@pm.me and IRC. I am in most of the #gentoo IRC groups and my nick is #LabBrat.
Links
- [Link] – gentoo_update CLI repository
- [Link] – Mobile App repository
August 21 2023
Week 12 report on porting Gentoo packages to modern C
Hello all, hope you’re doing well. This is my week 12 report for my
project “Porting Gentoo’s packages to modern C”
Similar to last week I took up bugs from the tracker randomly and
patched them, sending patch upstream whenever possible. Unfortunately,
nothing new or interesting.
Also been working with Juippis on masking firefox-bin and rust-bin in
glibc llvm profile, Juippis has for now reverted the commit masking
those bin packages, but likely a proper fix will be committed soon.
Just warping things up for final review. I’m also in 1:1 contact with
Sam in case there is some major work needed on a particular section of
my project or a package.
And to be honest, it not really much, I’ve been under the weather a bit
and busy with some IRL stuff.
This week I’ve some free time which I plan on dedicating to lapac and
fortran bug on llvm profile. With that solved, we will be able to close
a good number of bugs sci package related bugs and also some qemu
related bugs (as that pull some packages like apack and lapack). I’ll
probably also sit with Sam for this one, hopefully we’ll be able to calk
something out.
EDIT
I forgot to mention that this is going to be the last week, so I’ll wrap things up after talking with my mentors. Also will create a separate blog post that will link all of my work throughout the weeks in brief and will be used as the final submission.
Till then see yah!
August 20 2023
Week 11+12 Report, Automated Gentoo System Updater
This article is a summary of all the changes made on Automated Gentoo System Updater project during weeks 11 and 12 of GSoC.
Project is hosted on GitHub ( gentoo_update and mobile app).
Progress on Weeks 11 and 12
During last 2 weeks I’ve completed app UI and Firebase backend. Most of the work is done!
I’m not entirely pleased with how the backend works. In Firebase, I ended up using:
After a user authenticates using anonymous login, a token is automatically registered in Firestore. This token is later used by gentoo_update to send reports. Cloud Functions manage the token’s creation. In fact, all database write operations are handled by Cloud Functions, with users having read-only access to the data they’ve created. Here is how to send the report via token:
export GU_TOKEN="<token ID>"
gentoo-update --send-report mobile
Internally, gentoo-update talks to a Cloud Function. This function checks the token, then saves the report in Firestore for the user to access.
This differs from the original idea, where I didn’t intend to save reports in Firestore. The initial plan was to have the client side listen and let Firebase route report content from the Gentoo system to the app. But this method often missed reports or stored them incorrectly, causing them to vanish from the app. To solve this, I chose to save the reports and tokens, but with encryption.
I’ve came up with a solution to create a custom backend for the app, which users will be to self-host, more about in the Challenges section.
Apart from the web app, I’ve fixed some minor issues in gentoo-update and pushed the latest ebuild version to GURU repository (commit link).
Challenges
While Firebase offers a quick way to set up a backend, it has its drawbacks:
- Not all its best features are free.
- Some of its operations aren’t transparent.
- It doesn’t offer self-hosting.
- Its rate-limiting and security features aren’t as strong as needed. To tackle these concerns, I’m considering a custom backend using this tech stack: Linux + Docker + Python/Django + MongoDB + Nginx.
Here’s a breakdown:
- Django will serve as the backend, handling tasks similar to Cloud Functions.
- MongoDB, a document database, will take Firestore’s place.
- Nginx adds extra capabilities for rate-limiting, load balancing, and security checks.
If necessary, MongoDB can be swapped out for a relational database because the backend will heavily utilize ORM. The same flexibility applies to Nginx.
A highlight of this approach is that everything can be defined in a Docker Compose file, simplifying self-hosting for users.
Plans for Week 13 (final week  )
)
Here is my plan for the final week of GSoC’2023:
- Add encryption to the Firestore. I don’t want any user data to be stored in plain text.
- Improve some UI elements and add a pop-up with commands to copy/paste.
- Publish mobile app to Playstore.
- Write a detailed blog post on how to use the whole thing.
- Writa a post on forums.
August 14 2023
Week 11 report on porting Gentoo packages to modern C
Hello all, hope you’re doing well. This is my week 11 report for my
project “Porting Gentoo’s packages to modern C”
Similar to last two weeks I took up bugs from the tracker randomly and
patched them, sending patch upstream whenever possible. Unfortunately,
nothing new or interesting.
I’ve some open PRs at ::gentoo that I would like to work on and get
reviews on from mentor/s.
This coming week is going to be the last week, so I would like to few more bugs and
start working on wrapping things up. However, I don’t plan on abandoning
my patching work for this week (not even after GSoC) as there is still
lots interesting packages in the tracker.
Till then see yah!
August 07 2023
Week 9+10 Report, Automated Gentoo System Updater
This article is a summary of all the changes made on Automated Gentoo System Updater project during weeks 9 and 10 of GSoC.
Project is hosted on GitHub (gentoo_update and mobile app).
Progress on Weeks 9 and 10
I have finalized app architecture, here are the details:
The app’s main functionality is to receive notification from the push server. For each user, it will create a unique API token after authentication (there is an Anonymous option). This token will be used by gentoo_update to send the encrypted report to the mobile device using a push server endpoint. Update reports will be kept only on the mobile device, ensuring privacy.
After much discussion, I decided to implement app’s backend in Firebase. Since GSoC is organized by Google, it seems appropriate to use their products for this project. However, future plans include the possibility of implementing a self-hosted web server, so that instead of authentication user will just enter server public IP and port.
Example usage will be something like:
- Download the app and sign-in.
- App will generate a token, 1 token per 1 account.
- Save the token into an environmental variable on Gentoo Linux.
- Run
gentoo_update --send-report mobile - Wait until notification arrives on the mobile app.
I have also made some progress on the app’s code. I’ve decided to host it in another repository because it doesn’t require direct access to gentoo_update, and this way it will be easier to manage versions and set up CI/CD.
Splitting tasks for the app into UI and Backend categories was not very efficient in practice, since two are very closely related. Here is what I have done so far:
- Create an app layout
- Set up Firebase backend for the app
- Set up database structure for storing tokens
- Configure anonymous authentication
- UI elements for everything above
Challenges
I’m finding it somewhat challenging to get used to Flutter and design an modern-looking app. My comfort zone lies more in coding backend and automation tasks rather than focusing on the intricacies of UI components. Despite these challenges, I am 60% sure that in end app will look half-decent.
Plans for Week 11
After week 11 I plan to have a mechanism to deliver update reports from a Gentoo Linux machine.
August 06 2023
Week 10 report on porting Gentoo packages to modern C
Hello all, I’m here with my week 10 report of my project “Porting
gentoo’s packages to modern C”
So apart from the usual patching of packages from the tracker the most
significant work done this week is getting GNOME desktop on llvm
profile. But it is to be noted that the packages gui-libs/libhandy,
dev-libs/libgee and sys-libs/libblockdev require gcc fallback
environment. net-dialup/ppp was also on our list but thanks to Sam its
has been patched [0] (and fix sent upstream). I’m pretty sure that
the same work around would work on musl-llvm profile as well. Overall
point being we now have two DEs on llvm profile, GNOME and MATE.
Another thing to note is currently gui-libs/gtk-4.10.4 require
overriding of LD to bfd and OBJCOPY to gnu objcopy, it is a dependency
for gnome 44.3.
Unfortunately, time is not my friend here and I’ve got only two weeks
left. I’ll try fix as many as packages possible in the coming weeks,
starting with the GNOME dependencies.
Meanwhile lot of my upstream patches are merged as well, hope remaining
ones get merged as well, [1][2] to name a few.
Till then, see ya!
[0]: https://github.com/gentoo/gentoo/pull/32198
[1]: https://github.com/CruiserOne/Astrolog/pull/20
[2]: https://github.com/cosmos72/detachtty/pull/6
August 02 2023
Weekly report 9, LLVM-libc
Hi! This week I’ve pretty much finished the work on LLVM/Clang support
for Crossdev and LLVM-libc ebuild(s). I have sent PRs for Crossdev and
related ebuild changes here:
https://github.com/gentoo/crossdev/pull/10
https://github.com/gentoo/gentoo/pull/32136
This PR includes changes for compiler-rt which are always needed for
Clang crossdev, regardless of libc. There are also changes to musl,
kernel-2.eclass (for linux-headers), and a new eclass, cross.eclass.
I made a gentoo.git branch that has LLVM-libc, libc-hdrgen ebuilds and a
gnuconfig patch to support
LLVM-libc. https://github.com/gentoo/gentoo/compare/master…alfredfo:gentoo:gentoo-llvm-libc. I
want to merge Crossdev changes and ebuilds before merging
this. Previously all autotools based projects would fail to configure on
LLVM-libc because there was no gnuconfig entry for it.
I have also solved the problem from last week not being able to compile SCUDO
into LLVM-libc directly. This was caused by two things, 1) LLVM-libc
only checked for compiler-rt in LLVM_ENABLE_PROJECTS, not
LLVM_ENABLE_RUNTIMES which is needed for using “llvm-project/runtimes”
as root source directory (“Runtimes build”).
Fix commit:
https://github.com/llvm/llvm-project/commit/fe9c3c786837de74dc936f8994cd5a53dd8ee708
2) Many compiler-rt configure tests would fail because of LLVM-libc not
supporting dynamic linking, and therefore disable the build of
SCUDO. This was fixed by passing
-DCMAKE_TRY_COMPILE_TARGET_TYPE=STATIC_LIBRARY. So now I no longer need
to manually compile the source files and append object files into
libc.a, yay!
Now I will continue to fix packages for using LLVM-libc Crossdev, or
more likely, add needed functionality into LLVM-libc. I will of course
also fix any comments I get on my PRs.
—
catcream
July 30 2023
Week 9 report on porting Gentoo packages to modern C
Hello all, hope you’re doing well. This is my week 9 report for my
project “Porting Gentoo’s packages to modern C”
Similar to last week, I picked up bugs at random and started submitting
patches. But this time I made sure to check out the upstream and send in
patches whenever possible, if it turned out to be difficult or I
couldn’t find upstream I made sure to make a note about it in the PR
either via commit message or through a separate comment. This way it’ll
help my Sam keep track of things and my progress.
Apart from that nothing new or interesting unfortunately.
Coming next week the plan is the same, pick up more bugs and send in
PRs, both in ::gentoo and upstream whenever possible. I also have some
free time coming week, so plan to make up for lost time during my sick
days in the coming week, as there still lots of packages that require
patching.
I would like to note here, that I made an extra blog post last week
about setting testing environment using lxc and the knowledge about
using gentoo’s stage-3 tarballs to create custom lxc gentoo images. I
don’t really expect anyone following it or using it, mainly put that up
for future reference for myself.
Till then, see ya!
July 29 2023
Genkernel in 2023
I really wanted to look into the new kernel building solutions for Gentoo and maybe migrate to dracut, but last time I tried, ~1.5 years ago, the initreamfs was now working for me.
And now in 2023 I’m still running genkernel for my personal boxes as well as other servers running Gentoo.
I guess some short term solutions really become defined tools :P
So this is how I rebuild my kernel nowadays:
-
Copy old config
1 2
cd /usr/src cp linux-6.1.38-gentoo/.config linux-6.1.41-gentoo/
-
Remove old kernel build directories
1rm -r linux-6.1.31-gentoo
-
Run initial preparation
1( eselect kernel set 1 && cd /usr/src/linux && make olddefconfig )
-
Call genkernel
1 2 3 4 5 6 7 8 9 10 11 12
genkernel \ --no-menuconfig \ --no-clean \ --no-clear-cachedir \ --no-cleanup \ --no-mrproper \ --lvm \ --luks \ --mdadm \ --nfs \ --kernel-localversion="-$(hostname)-$(date '+%Y.%m.%d')" \ all
-
Rebuild the modules
If in your
/etc/genkernel.confyou haveMODULEREBUILDturned off, then also call emerge:1emerge -1 @module-rebuild
July 24 2023
Weekly report 8, LLVM libc
Hi! This (and last week) I’ve spent my time polishing the LLVM/Clang
crossdev work. I have also created ebuilds for llvm-libc, libc-hdrgen
and also the SCUDO allocator. But I will probably bake SCUDO into the
llvm-libc ebuild instead actually.
One thing I have also made is a cross eclass that handles cross
compilation, instead of having the same logic copy-pasted in all
ebuilds. To differentiate a “normal” crossdev package and LLVM/Clang
crossdev I decided to use “cross_llvm-${CTARGET}” as package category
name. This is necessary since you need some way to tell the ebuild about
using LLVM for cross. My initial idea was to handle all this in the
crossdev script, but crossdev ebuilds are self-contained, and you can do
something like “emerge cross_llvm-gentoo-linux-llvm/llvm-libc” and it
will do the right thing without running emerge from crossdev. Hence I
need to handle cross compilation in the ebuilds themselves, using the
eclass. Me and sam are not sure if a new eclass is the right thing to
do but I will continue with it until I get some more thoughts as we can
just inline everything later without wasting any work.
I feel pretty much done now except for baking SCUDO directly into the
llvm-libc ebuild. Actually it is very simple to do but I got some issues
with libstdc++ when using llvm/ as root source directory for the libc
build, which is necessary to use when compiling SCUDO. Previously I used
runtimes/ as root directory, and that worked without issue. Currently to
work around this you can just compile the source files in
llvm-project/compiler-rt/lib/scudo/standalone and append the object
files into libc.a. LLVM libc then just works with crossdev and you
can compile things with the emerge wrapper as usual, but currently a lot
of autotools things break due to me not having specified gnuconfig for
llvm-libc yet.
I had a lot of trouble last week with sonames when doing an aarch64 musl
crossdev setup and running binaries with qemu-user, however it turned
out it was just a warning and it worked after setting LD_LIBRARY_PATH as
envvar to qemu-user. I spent a loong time on this.
Currently I will need to upstream changes to compiler-rt ebuild, musl
llvm-libc ebuild, libc-hdrgen, cross.eclass, and of course crossdev.
Next week I will send the changes upstream for review and continue work
on LLVM libc, most likely simple packages like ed, and then try to get
the missing pieces upstreamed to LLVM libc. fileno() is definitely
needed for ed.
Last week I did not write a blog post as I was in “bug hell” and worked
on a lot of small things at once and thought “if I just finish this I
can write a good report”, and then wednesday came, and I decided to just
do an overview of all my work for this weeks’ blog instead 
– —
catcream